作者:青春快乐的勇哥 | 来源:互联网 | 2023-09-01 09:06
篇首语:本文由编程笔记#小编为大家整理,主要介绍了06Hadoop框架HDFS读写流程相关的知识,希望对你有一定的参考价值。
文章目录
- HDFS读写流程
- FileSystem
- fileSystem是使用java代码操作hdfs的api接口
- 文件操作
- 目录操作
- Client读取多副本文件过程
- Remote Procedure Call
- HDFS中的block、packet、chunk
- 数据存储:读文件
- 读文件流程分析
- 数据存储:写文件
- 写文件流程分析
- hdfs的HA (高可用)
- HA的failover原理
- HDFS的federation
- federation架构图-1
- federation架构图-2
- hdfs常见问题
HDFS读写流程
FileSystem
fileSystem是使用java代码操作hdfs的api接口
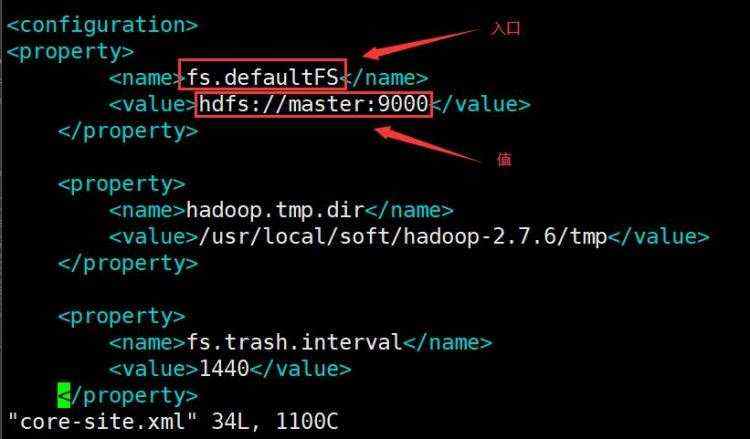
文件操作
- create写文件
- open读取文件
- delete删除文件
目录操作
- mkdirs创建目录
- delete删除文件或目录
- listStatus列出目录的内容
- getFileStatus 显示文件系统的目录和文件的元数据信息
- getFileBlockLocations显示文件存储位置
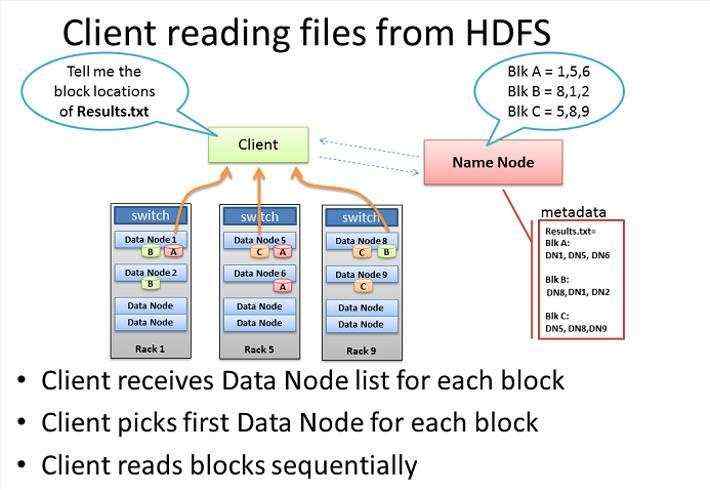
Client读取多副本文件过程
Remote Procedure Call
- RPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
- RPC采用客户机(client)/服务器(server)模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
- hadoop的整个体系结构就是构建在RPC之上的(见org.apache.hadoop.ipc)。
HDFS中的block、packet、chunk
这个大家应该知道,文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
例如,在client端向DataNode传数据的时候,HDFSOutputStream会有一个chunk buff,写满一个chunk后,会计算校验和并写入当前的chunk。之后再把带有校验和的chunk写入packet,当一个packet写满后,packet会进入dataQueue队列,其他的DataNode就是从这个dataQueue获取client端上传的数据并存储的。同时一个DataNode成功存储一个packet后之后会返回一个ack packet,放入ack Queue中。
数据存储:读文件
- 1、client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
- 2、就近挑选一台datanode服务器,请求建立输入流。
- 3、DataNode向输入流中中写数据,以packet为单位来校验。
- 4、关闭输入流
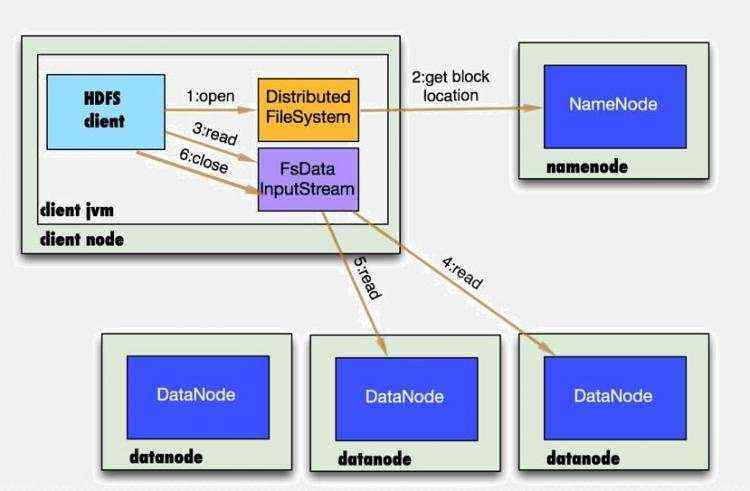
读文件流程分析
- 1、首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例。
- 2、DistributedFileSystem通过rpc获得文件的第一个block的locations,同一block按照副本数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面。
- 3、前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接。
- 4、数据从datanode源源不断的流向客户端。
- 5、如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
- 6、如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流。
- 7、如果在读数据的时候,DFSInputStream和datanode的通讯发生异常,就会尝试正在读的block的排第二近的datanode,并且会记录哪个datanode发生错误,剩余的blocks读的时候就会直接跳过该datanode。DFSInputStream也会检查block数据校验和,如果发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其他的datanode上读该block的镜像。
- 8、该设计的方向就是客户端直接连接datanode来检索数据并且namenode来负责为每一个block提供最优的datanode,namenode仅仅处理block location的请求,这些信息都加载在namenode的内存中,hdfs通过datanode集群可以承受大量客户端的并发访问。
数据存储:写文件
- 1、客户端向NameNode发出写文件请求。
- 2、检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
- 3、client端按128MB的块切分文件。
- 4、client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
- 5、每个DataNode写完一个块后,会返回确认信息。
- 6、写完数据,关闭输输出流。
- 7、发送完成信号给NameNode。
注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。
最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性.
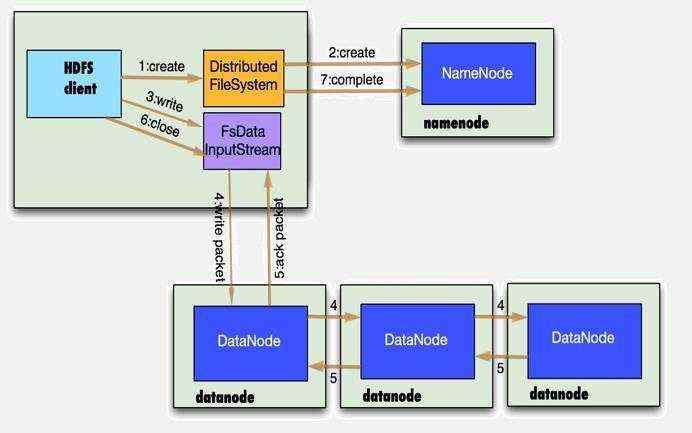
写文件流程分析
- 1、客户端通过调用DistributedFileSystem的create方法创建新文件。
- 2、DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前,namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常。
- 3、前两步结束后会返回FSDataOutputStream的对象,与读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream.DFSOutputStream可以协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data quene。
- 4、DataStreamer会去处理接受data queue,他先问询namenode这个新的block最适合存储的在哪几个datanode里,比如副本数是3,那么就找到3个最适合的datanode,把他们排成一个pipeline.DataStreamer把packet按队列输出到管道的第一个datanode中,第一个datanode又把packet输出到第二个datanode中,以此类推。
- 5、DFSOutputStream还有一个对列叫ack queue,也是由packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
- 如果在写的过程中某个datanode发生错误,会采取以下几步:
- 1)、pipeline被关闭掉;
- 2)、为了防止丢包 ack queue里的packet会同步到data queue里;
- 3)、把产生错误的datanode上当前在写但未完成的block删掉;
- 4)、block剩下的部分被写到剩下的两个正常的datanode中;
- 5)、namenode找到另外的datanode去创建这个块的复制。
- 当然,这些操作对客户端来说是无感知的。
- 6、客户端完成写数据后调用close方法关闭写入流。
- 7、DataStreamer把剩余得包都刷到pipeline里然后等待ack信息,收到最后一个ack后,通知datanode把文件标示为已完成。
hdfs的HA (高可用)
zk:指zookeeper,负责协调,监控
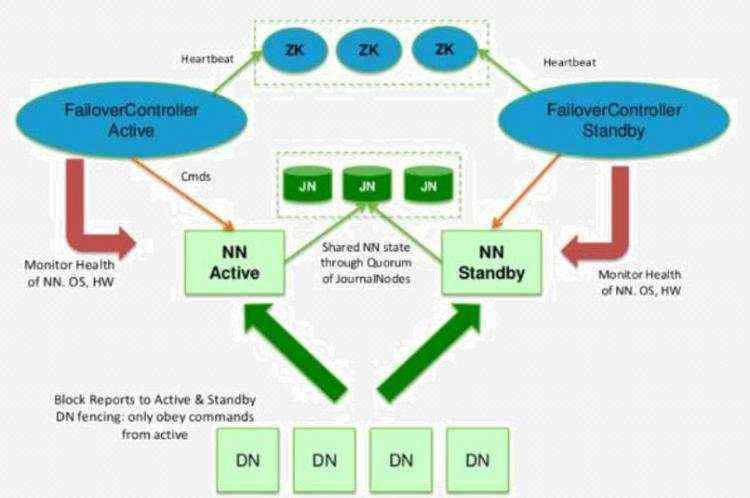
HA的failover原理
- HDFS的HA,指的是在一个集群中存在两个NameNode,分别运行在独立的物理节点上。在任何时间点,只有一个NameNodes是处于Active状态,另一种是在Standby状态。 Active NameNode负责所有的客户端的操作,而Standby NameNode用来同步Active NameNode的状态信息,以提供快速的故障恢复能力。
- 为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向两个NN发送block位置信息外,还构建了一组独立的守护进程”JournalNodes”,用来同步Edits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上。而Standby NN负责观察JNs的变化,读取从Active NN发送过来的Edits信息,并更新自己内部的命名空间。一旦ActiveNN遇到错误,Standby NN需要保证从JNs中读出了全部的Edits,然后切换成Active状态。
使用HA的时候,不能启动SecondaryNameNode,会出错。
HDFS的federation
- HDFS Federation设计可解决单一命名空间存在的以下几个问题:
- 1、 HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再像1.0中那样由于内存的限制制约文件存储数目。
- 2、性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
- 3、良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
federation架构图-1
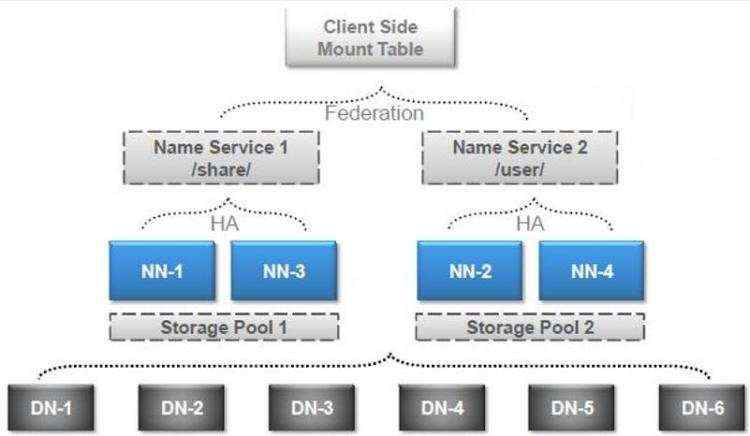
federation架构图-2
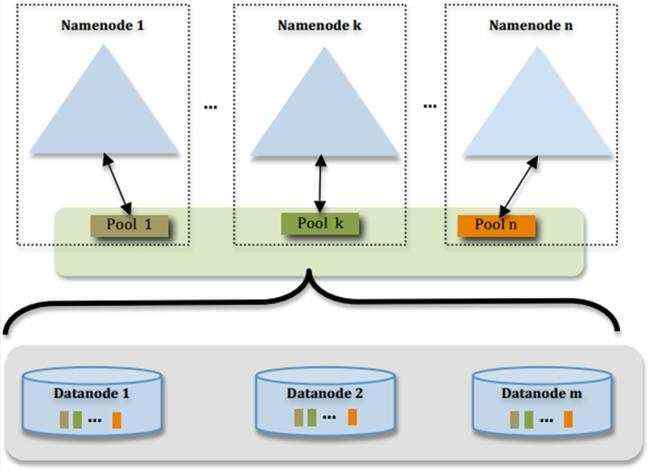
hdfs常见问题
- 集群启动失败
- hdfs文件无法操作
- 一般是因为处于安全模式下
- 离开安全模式:hdfs dfsadmin -safemode leave
- 进入安全模式:hdfs dfsadmin -safemode enter
- 查看安全模式:hdfs dfsadmin -safemode get
到底啦!觉得靓仔的文章对你学习Hadoop有所帮助的话,一波三连吧!q(≧▽≦q)









 京公网安备 11010802041100号
京公网安备 11010802041100号